By Jesse Pollak, Head of Engineering, Consumer
Over the last two weeks, Coinbase experienced two outages that impacted our ability to serve our customers. For both of these incidents, we promptly discovered the root causes and restored service. However, we want to provide a deeper look at what went wrong and what we’re doing about it going forward. We are committed to making Coinbase the easiest, most trusted place to buy, sell, and manage your cryptocurrency.
4/29 Incident
From 10:28 PDT to 10:40 PDT on April 29, 2020, the API that powers coinbase.com and our mobile applications became unavailable for our customers globally. This was followed by 30 minutes of stability, and then a period of instability from 11:12 PDT to 12:11 PDT, during which we sustained 20 minutes of full unavailability and 40 minutes of degraded performance with elevated error rates. At 12:11 PDT, full service was restored and all systems began operating normally.
This issue affected customers’ ability to access Coinbase and Coinbase Pro UIs, and did not impact trading via our exchange APIs or the health of the underlying markets. It was caused and perpetuated by two separate, but related, root causes.
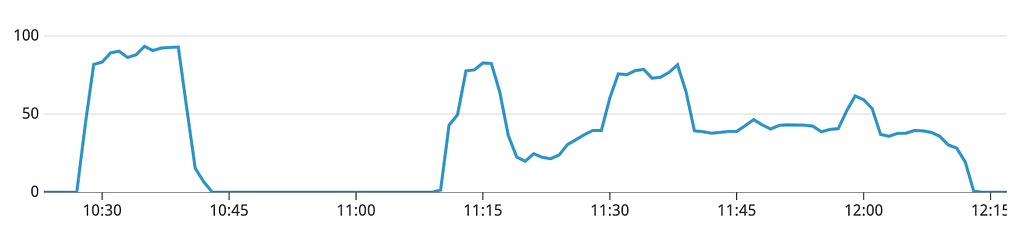
The initial incident was triggered at 17:28 PDT by an increase in the rate of connections to one of our primary databases. This connection rate increase was the result of a deploy creating new connections while our systems were scaled to respond to elevated traffic at the time. When this spike in connections occurred, the host operating system for the database began rejecting new TCP connections to the host, which triggered degraded operations and restarts in the routing layer for the database. When this occurred, our monitoring began reporting an elevated error rate across all API requests that touched the impacted database.
In response to the failures in the routing layer and the corresponding operational failures, our systems attempted to reconnect in order to retry these operations. Unfortunately, due to improper closed connection handling and lack of support for timing jitter in new connection creation, our systems “connection stormed” the database. This connection storm triggered the same failure we saw on other members of the routing layer, preventing new connections to be established. While the initial database was able to recover at 10:40 PDT, this same failure mode occurred with three other, separate database instances, creating the second period of unavailability from 11:12 PDT to 12:11 PDT.
In response to this failure, we’re rolling out a number of changes. First, we’re changing our database deployment topology to reduce our overall connection count, limit connection spikes, and separate the routing and daemon processes of the database to limit competition for host resources. Second, we’re resolving the issue with the driver closed connection logic and implementing better jitter to prevent connection storming when this failure mode occurs. Finally, we’re rolling out safeguards that will allow us to contain the impact of future database failures to as small a subset of requests as possible.
5/9 Incident
From 17:17 PDT to 18:00 PDT on May 9, 2020, the API that powers coinbase.com and our mobile applications experienced an elevated error rate. The error rate peaked at 17:24 PDT and gradually decayed until the issue was fully resolved at 18:00 PDT. This issue affected customers’ ability to access Coinbase and Coinbase Pro UIs, and did not impact trading via our exchange APIs or the health of the underlying markets.

At 17:18 PDT, alongside an increase in traffic due to market volatility, our monitoring detected elevated latency and error rates in our API and alerted our engineering team to the issue. In response to these alerts, our engineering team observed elevated latency across all outgoing HTTP requests on the application instances which serve our API traffic. This manifested in our monitoring as dramatically increased % of time spent per API request in outgoing HTTP requests.
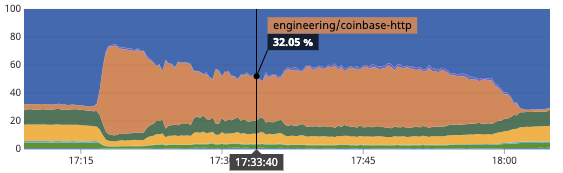
As a result of this increase in latency, we saw an elevated error rate due to timeouts while attempting these outgoing HTTP requests. The elevated error rate was amplified by our load balancer killing otherwise-healthy application instances that failed health checks. The failed health checks were a result of their request queue being saturated due to this shift in request shape.
Upon further investigation, we identified that the increase in latency was due to instance-level rate limiting of the DNS queries used to serve these HTTP requests. As traffic reduced due to the error rate, we dipped below the rate limit, leading to the gradual decay of the error rate. In parallel, we rolled out a previously in-flight change to add per-instance DNS caching, bringing us back into the non-rate-limited range for global DNS queries and ensuring the failure mode would not appear again.
Beyond addressing the specific root cause for this incident, we are making a number of improvements to increase availability in the event of future similar failures. First, we’re adjusting our health check logic to ensure that saturated, but otherwise healthy, application instances are not automatically removed from the load balancer. Second, though this incident impacted all HTTP requests, we’re rolling out improved tooling to ensure we can quickly identify and shutdown errant external services that increase latency. Finally, as with the 4/29 incident, we’re rolling out safeguards that will allow us to contain the impact of future HTTP failures to as small a subset of requests as possible.
Looking ahead
Both of these incidents impacted our ability to serve Coinbase customers at critical moments. One of our company values is continuous learning and we are committed to taking the learnings from these episodes to improve Coinbase. If you’re interested in working on challenging availability problems and building the future of the cryptoeconomy, come join us!
Incident Post Mortem: April 29 and May 9, 2020 was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
via The Coinbase Blog - Medium https://blog.coinbase.com/incident-post-mortem-april-29-and-may-9-2020-56494decab9f?source=rss----c114225aeaf7---4
No comments:
Post a Comment